Students: Diego Vaz Caetano, Josué Dias Cardoso and Luana Guimarães Piani Ferreira
Collaborators: Raphael Abreu, João Quadros, Joel Santos
Advisors: Leonardo Lignani, Eduardo Ogasawara

Abstract
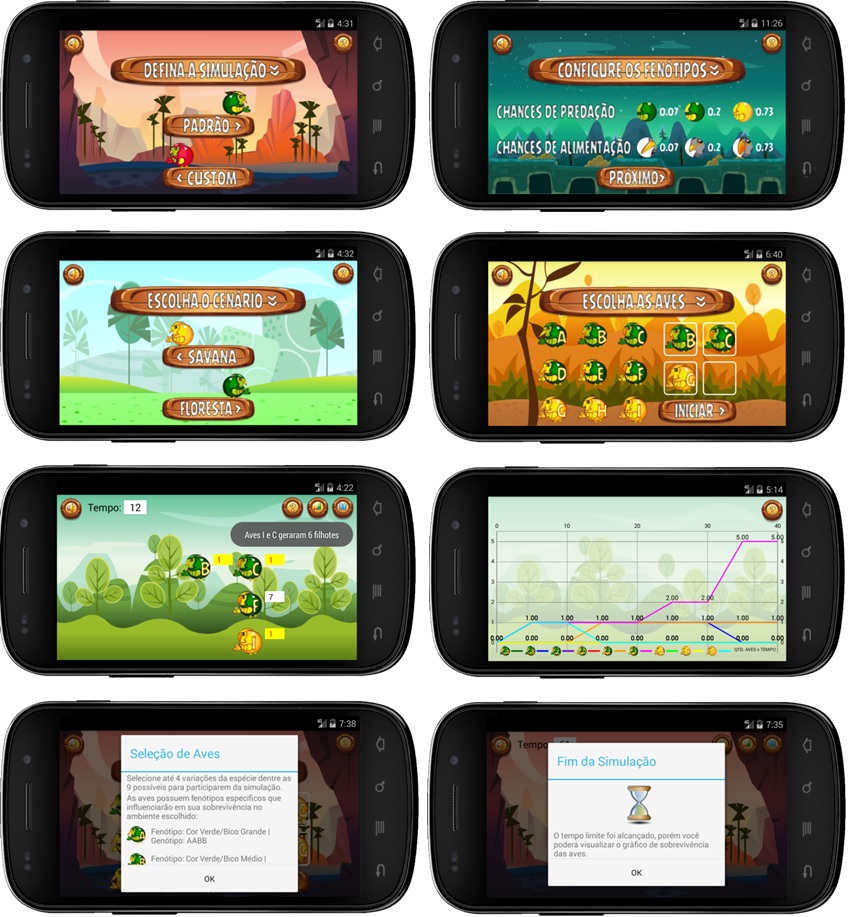
The use of simulators as educational tools aims to increase students’ engagement in classes and seems to help them to understand difficult concepts. They can be used in natural science classes as an alternative for practical or experimental approaches when the time and space scales required are not compatible with the scholar environment. Through interactive simulators, students can explore the topic under study. Discoveries are made, predictions are confirmed or refuted by subsequent simulations, enhancing the comprehension of the phenomenon. This article presents Sim-Evolution, an educational simulator to help teachers presenting Charles Darwin’s Theory of Evolution by Natural Selection (TENS). Our intention with Sim-Evolution is to enable students to practice and comprehend TENS as a process that occurs at the population level. Given that it focuses on High School level, its interface was designed to be joyful, helping to engage students. We developed Sim-Evolution focusing on three basic biological principles that structure TENS: (i) variation, (ii) heredity and (iii) selection. Also, simulation design is based on Mendelian Genetics and population genetics. However, we intended that knowledge of these areas should not be a requisite for using Sim-Evolution. Therefore, students can observe laws of evolution and the genetic properties (genotypes) by analyzing species phenotypes and surviving populations. Sim-Evolution was evaluated by High-School students in a Biology class. Experiments indicate that students could observe TENS as a population process and were able to identify the principles of variation, heredity, and selection by indirect analysis from living species phenotypes.
App
Sim-Evolution at Google Play store
User manual

Experimental Evaluation
Evaluation Procedure
Evaluation Form
Source code at GitHub
Privacy policy
We understand that user privacy must be protected and, while our application does not collect any personal information from the user or device, we are committed to transparency and therefore feel obligated to develop this Privacy Policy, the To help the user understand what data we collect, why we collect them, and what we do with them.
Information we collect and how we use it
Our application has educational purposes and was developed under the coordination of the Computer Science Departament of CEFET/RJ (http://eic.cefet-rj.br). We collect the following application information for statistical research purposes:
- Application Name
- Application version
- Date / Time of application usage
- Simulation duration time (reported in simulation time counter)
- Type of environment used for the simulation (Forest, Savannah or Custom)
- Types of birds selected for the beginning of the simulation
- Types of birds existing at the close of the simulation, with their respective quantities
The information is collected and transmitted automatically at the end of each simulation when the user exits the simulation screen.
We use this information for application usage search purposes and also for possible application feature enhancements.
When this Privacy Policy applies
Our Privacy Policy applies to Sim-Evolution and its built-in features but excludes services that Google offers on Android devices.
Our Privacy Policy does not apply to services offered by other companies or individuals, including products or websites that may be displayed to the user in search results, sites that may include Sim-Evolution services or other sites with links to our services. Our Privacy Policy does not control the information practices of other companies and organizations that advertise our services and may use cookies, pixel tags, and other technologies to deliver relevant ads.
If you have any questions or concerns about our privacy policy or our practices, please contact us at gpcacefetrj@gmail.com.