Authors: Alice Sternberg, Diego Carvalho, Leonardo Murta, Jorge Soares and Eduardo Ogasawara
Federal Center for Technological Education of Rio de Janeiro (CEFET/RJ)
Abstract: In this paper, we applied data indexing techniques combined with association rules to unveil hidden patterns of flight delays. Considering Brazilian flight data and guided by six research questions related to causes, moments, differences, and relationships between airports and airlines, we evaluated and quantified all attributes that may lead to delays, showing not only the main patterns, but also their chances of occurrence in the entire network, in each airport and airline. We observed that Brazilian flight system has difficulties to recover from previous delays and when operating under adverse meteorological conditions, delays occurrences may increase up to 216%.
Acknowledgments: The authors thank CNPq and FAPERJ for partially sponsoring this research.
Arules Package for R: Functions for mining association rules and frequent itemsets. The Apriori algorithm is intended to be used on the generation of association rules for flight delays. Restricting the right-hand side of the rule to a flight delay may show its reasons on the left-hand side. For this purpose, in order to understand domestic delays in Brazil, a data set containing flight and meteorological data was built and evaluated through the association rules generated by Apriori.
- Available at CRAN: https://cran.r-project.org/web/packages/arules/index.html
- Reference manual: https://cran.r-project.org/web/packages/arules/arules.pdf
#Install Apriori package
install.packages("arules")
#Load Arules package
library("arules")
data(flightBR)
rules_delay <- apriori(flightBR,parameter=list(supp = 0.00077, conf = 0.2276, minlen=2, maxlen= 4, target = "rules"),
appearance=list(rhs = c("delay_dep=1"),default="lhs"), control=NULL)
#delay_dep=1 means a departure delay or a cancellation
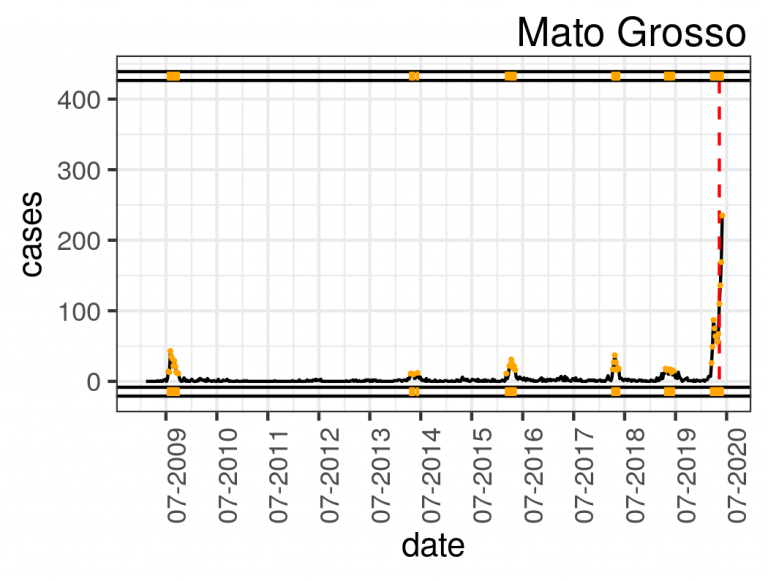
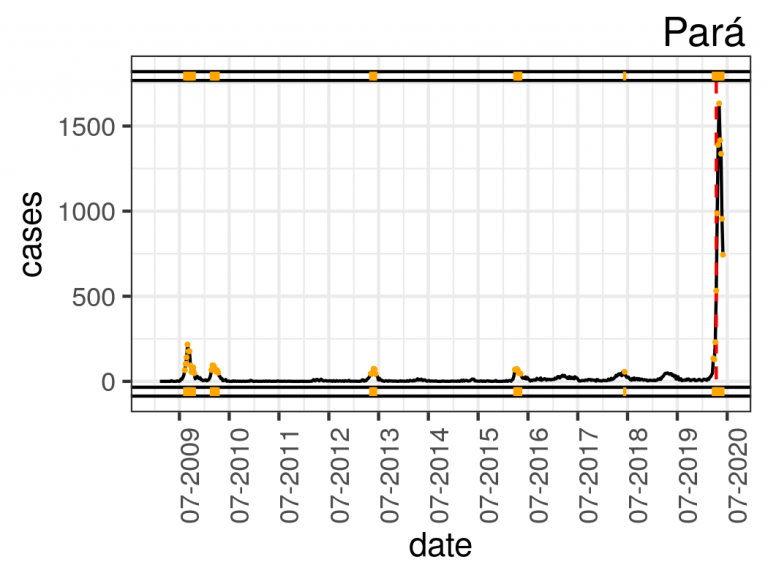
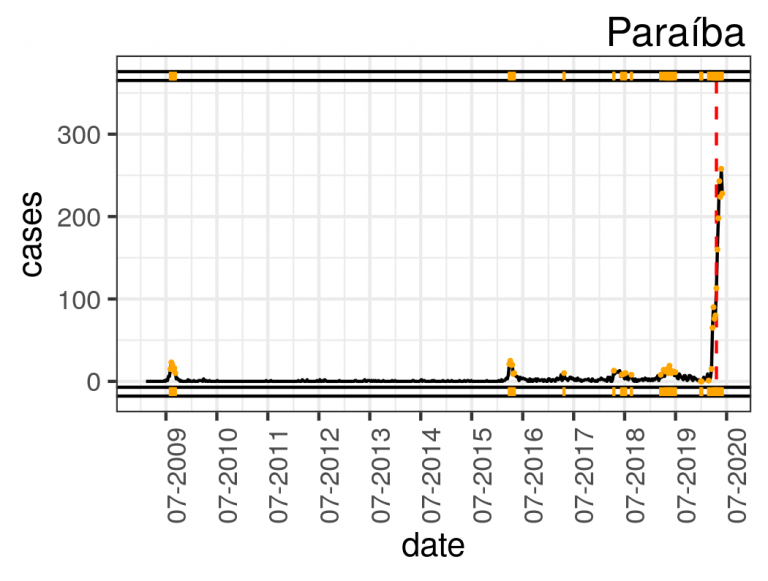
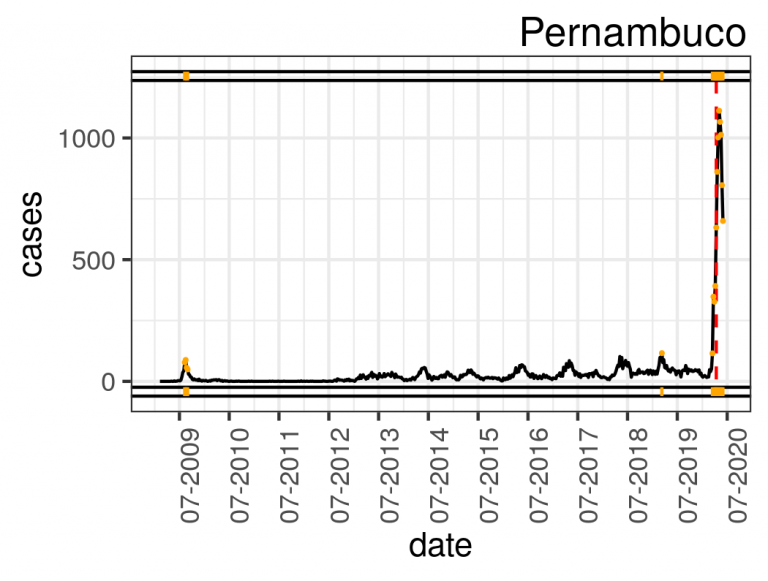
The Arules R-Package enables the generation of association rules using the Apriori algorithm. Restricting the right-hand side of the rule to delays and setting the thresholds for support, confidence and minimum and maximum lengths, we obtain the conditions that may explain the reasons for flight delays on the left-hand side of the rules. For this purpose, we built the flightBR data set after some preprocessing stages, such as integration of multiple sources, cleaning of discrepancies and outliers, selection of the main airports and airlines and transformation, in which we created 12 derived attributes using concept hierarchies, binning, and temporal aggregation. Thus, the flightBR data set contains Brazilian domestic and commercial flights data between January 2009 and February 2015.
flightBR data set: flightBR.RData
Firstly, the apriori function was applied to this dataset considering a support of 0.00077 (approximately equivalent to once per day), a confidence of 0.2276 (the total percentage of delays of the dataset), a minimum length of 2 and maximum length from 2 to 4, generating the following three sets of rules.
Rules of maximum length = 2: rules2.csv
Rules of maximum length = 3: rules3.csv
Rules of maximum length = 4: rules4.csv
Then, the rules were evaluated based on their lifts. The lift is a correlation measure between the conditions on the left-hand side and the consequent on the right-hand side, which in our case is a flight delay. When greater than 1, the chances of experiencing a delay grow with the increase of the lift.
We also generated some specific sets of rules considering some important attributes verified on the first analysis, such as the year of departure, the time of the day and their relationship with airports and the relationship between airlines and airports. For this purpose, support and confidence were very low in order to consider all the situations experienced by the flightBR flights.
Year of departure: year.csv
Time of departure: time_of_day.csv
Time of departure and airport: time_airport.csv
Airline and airport: airline_airport.csv
Finally, we add arrival attributes to the flightBR dataset, creating the flightBR_arr dataset, in order to compare departure and arrival delays. Using very low support and confidence, we investigated when a late departure can be recovered and transformed into a punctual arrival and when a punctual departure leads to a delayed arrival.
flightBR_arr data set: flightBR_arr.RData
Late departures and punctual arrivals: late_dep_punctual_arr.csv
Punctual departures and late arrivals: punctual_dep_late_arr.csv